Overview
WrapRec is an open-source project, developed with C# which aims to simplify the evaluation of Recommender System algorithms. WrapRec is a configuration-based tool. All desing choices and parameters should be defined in a configuration file.
The easiest way to use WrapRec is to download the latest release, specify the details of experiments that you want to perform within a configuration file and run the WrapRec executable.
Get Started with a "Hello MovieLens" Example
MovieLens is one of the most widely-used benchmark datasets in Recommeder Systems research. Start to use WrapRec with a simple train-and-test scenario using the 100K version of this dataset.
To run the example Download the
Hello MovieLens exmaple
and extract it in the same folder that contains WrapRec executable. Run the example by the following command.
In Windows, you should have .Net Framework,
and in Linux and Mac you should have .Net Mono installed to run WrapRec.
Windows
wraprec.exe sample.xml
Linux and Mac
mono wraprec.exe sample.xml
The example performs four simple experiment with MoviLens 100K dataset. The result of experiments will be stored
in a folder results with csv format. Check WrapRec Outputs to understand
more about the restuls and outputs of WrapRec.
You can start your experiments by modifying the sample configuration file. The configuration file is rather intuitive and easy to understand. Check Configuration section to undrestand the format of the configuration file in WrapRec.
WrapRec Architecture
WrapRec is designed based on the idea that for any evaluation experiment for Recommender Systems (and generally in Machine Learning), three main components should be present
- Model
- Defines the algorithm that is used to train and evalute Recommender System
- Split
- Specifies the data sources and how the data should be splitted for training and evaluation
- Evaluation
Context - Defines a set of evaluators to evaluate a trained model
The overal architecture of WrapRec is summerized in the Figure below. WrapRec is not about implementation of
actual algorithms for recommender systems. Instead, it provides functionalities to easily wrap exisiting algorithms
into framework, to be able to perform extensive evaluation experiments in single framework.
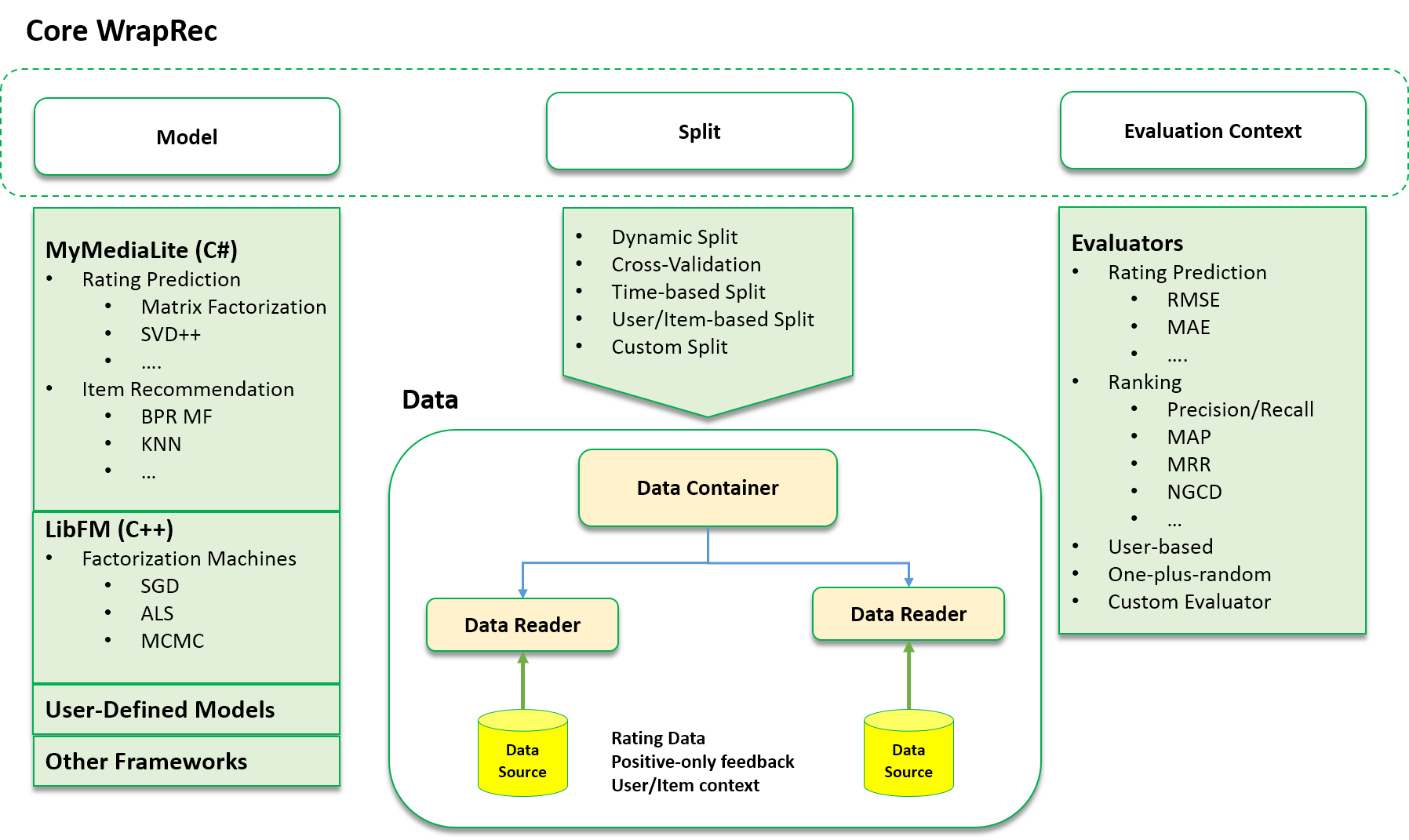
Building Blocks in WrapRec
To perform an evaluation experiment with WrapRec, three main building blocks are required.Model
Defines the algorithm that is used to train and evalute Recommender System
Currently WrapRec is able to wrap algorithms from two Recommender System toolkits: MyMediLite and LibFm. You can also plug your own algorithm to this framework. Check How to Extend WrapRec to learn how to extend WrapRec with your own algorithm or third party implementations.
Split
Specifies the data sources and how the data should be splitted for training and evaluation
In WrapRec data will be loaded through DataReader components. You can define in the configuration file
what is the input data, what is the format and how it should be loaded.
The data will be store in a DataContainer object.
An Split defines, how the data in DataContainer can be splited for training and evaluation.
WrapRec supports several splitting methods such as static, dynamic and Cross-Validation.
Evaluation Context
Defines a set of evaluators to evaluate a trained model
Evaluation Context is a component is WrapRec that consists of several Evaluators and store the results
of evaluations that are done with Evaluator objects.
Configuration File
In WrapRec all the settings and desing choices are defined in a configuration file.
The overal format of the configuration file is defined as follow.
- Components in the configuration file are loaded via Reflection and the parameters are dynamic. It means that you can specify the type of class and its properties and WrapRec creates the objects during runtime.
- Parameters can have multiple values. WrapRec detects all parameters with multiple values and run multiple experiments, as many times and the catesian product of all parameters.
- The three main components of an experiments (Model, Split and Evaluation Context) should be defined in the configuration file.
Experiment
In WrapRec evaluation experiments are defined in an experiment object.
In the configuration file an experiment is defined in an experiment
element.
experiments element, you can define as many experiment as you want.
experiments element is the starting point of parsing the configuration file
and runnig the experiments. You can specify which experiment(s) you want to run
using run attribute.
WrapRec Output
For each experiment that you run with WrapRec, two csv files will be generated.
The name of the files are [experimentId].csv and [experimentId].splits.csv.
The first file contains the results of experiment (in tab separated by default)
and the second file contains some statistics about the dataset and splits that is
used for that experiment. These two files are stored in the path that are specified
by the attribute resultsFolder. You can change the delimiter of the
generated csv files using attribute delimiter="[delimiter]".
WrapRec log some information when the experiments are running. You can change
the verbosity of experiments using the attribute verbosity. The values
can be trace (which log more details) and info.
Model
A model is defined with amodel element. There are two obligatory attributes
for a model element: id which is a name or id that you define for the model
, and class which is a full type name (including namespace) of the model class.
Advanced hint: If the class is defined in another assembly, the path
of the assembly should be prefix in the attribute class with a colon, that is,
[path to assmebly]:[full type name]
parameters.
Here is an example of a model definition:
The class specifies WrapRec wrapper class and the parameters specify the
properties of the model.
See detailed Documentation to see possible parameters
for different WrapRec models.
All parameters can have multiple values separated by comma. For each combinatio of parameters WrapRec creates an instance of the model object.
Hint: when you use a modelId in an experiment, for each combinatio of parameters one model instance will be used.
Split
An split is defined with an split element. With an split object
you specify what is the source of data and how should the data be splitted into
train and test sets. Using the attribute dataContainer you should specify
what is the data source of the split.
- Static
- Dynamic
- Cross-validation (cv)
- Custom
FeedbackSimpleSplit
class. You can make your own split logic by defining your own custom class and use
the type name in the parameter class.
Your custom split class should extend class WrapRec.Data.Split.
Check extending WrapRec to see how you can defined your ownd
types.
The attributes
trainRatios and numFolds can have multiple
values (comma separated). This means that the for each combination of parameters one
split object would be created.
Data
In WrapRec data are stored in a DataContainer object. The data is loaded
into the DataContainer object via DataReader objects.
A DataContainer should specify which DataReaders should be used to load data into
it. DataReaders specify how data should be loaded.
WrapRec.IO.CsvReader
to read csv data. If you are using this class there are few more parameters namely
hasHeader=[true|false] to indicate whether the csv has header or not
, delimiter=[delimiter] to specify delimiter in the csv file.
In addition you can specify the format of the csv file using the header=[comma separated fields] attribute.
Evaluation Context
An Evaluation Context is defined with a evalContext element.
An EvaluationContext object can have multiple evaluator objects that evaluate
a trained model. Evaluators are defined with an evaluator element.
Here is the fomrat of the evalContext element:
evaluator
element has an obligatory attribute class that specifies
the evaluator class. Depending on the evaluator class, more parameters
can be used. Here is an example of an evaluation context with multiple evaluators:
Here three evaluators are used. The firs two are simple RMSE ane MAE evalutors.
If you want to use ranking-based evaluators, you can use class
WrapRec.Evaluation.RankingEvaluators. Here you can specify
more parameters. This evaluator measures the following metrics:
- Precision
- Recall
- MAP
- MRR
- NDCG
- % of item coverage
candidateItemsMode. It can have one of the following values:
- training
- test
- union
- overlap
- explicit
Extending WrapRec
You can add your own logic to WrapRec or wrap other toolkits to it.
Currently WrapRec wraps two recommmender systems frameworks of
LibFm and MyMediaLite.
If you want to contribute on WrapRec, feel free to fork the
WrapRec github repository and
make a pull request.
You can also create your custom Experiment, Model, Split, DataReader and Evaluator
in a different assembly and use them in the configuration file.